생성 패턴
-. Factory Pattern: 객체의 생성 동작을 별도의 Class로 분리해 처리하거나 별도의 Method를 호출해 처리
-. Singleton Pattern: 선언된 Class로 복수 객체를 생성할 수 없도록 제한하며, 제한된 단일 객체는 공유와 충돌 방지
-. Factory Method Pattern: Factory Pattern에 추상화를 결합해 객체의 생성과 사용을 분리하는 방식으로, 선언된 Class의 객체를 직접 Code로 생성하지 않고 별도로 준비한 추상 Method에 생성 위임
-. Abstract Factory Pattern: Factory Method Pattern 보다 좀 더 큰 그룹 단위 객체를 생성/관리하는 방식으로 Factory에 Interface를 활용해 객체를 생성함으로써 Factory를 Factory의 군(Family)으로 변경
-. Builder Pattern: 추상 Factory Pattern을 확장한 Pattern으로 복잡한 구조의 복합 객체를 생성하기 위한 단계를 정의하고 각 단계 별 수행 동작을 변경하면서 Builder Pattern으로 생성
-. Prototype Pattern: 새로운 객체를 생성하지 않고 기존의 객체를 복제하는 방식으로 자원을 절약하는 Pattern
1. Class
: 객체지향 프로그래밍(OOP, Object Oriented Programming)의 핵심 개념으로, Data와 Data를 조작하는 함수를 하나의 논리적 단위로 묶는 사용자 정의 Data Type
1.1 주요 구성요소
-. Member Variant(멤버 변수): Class 내에서 Data를 저장하기 위한 변수로 객체의 속성을 나타냄
-. Member Function(멤버 함수): Class 내의 Data(Member Variant)를 조작하거나 동작을 정의하는 함수
-. Access Specifier(접근 제한자): Class Member의 접근 권한 제어
-. public: 외부에서 접근 가능
-. private: Class 내부에서만 접근 가능
-. protected: 파생 Class에서 접근 가능
-. Constructor(생성자): 객체 생성 시 자동으로 호출되는 함수로 Member Variant를 자동으로 초기화 하거나 객체 초기 설정에 사용
-. Destructor(소멸자): 객체가 소멸할 때 자동으로 호출되는 함수로 자원 해제 등에 사용
1.2 Class의 특징
-. Inheritance(상속): 기존 Class(부모 Class)의 속성과 가능을 다른 Class(자식 Class)가 물려받아 Code의 재사용성을 높임
-. Polymorphism(다형성): 같은 이름의 함수가 다른 동작을 수행할 수 있음
e.g., 함수 Over loading, 가상함수, ...
-. Encapsulation(캡슐화): Data와 함수를 하나로 묶고 외부에서 직접 접근 제한
-. Abstraction(추상화): 실제 Code를 개발하기 전에 구체적인 내용은 배제하고 개략적인 정보만 선언하는 것으로 추상적 개념과 실제 Code를 분리하는 효과가 있어 향후 개발 중인 Code를 예정하고 선언만으로 주변 가능을 작성할 수 있다는 장점이 있음
#include <iostream>
using namesapce std;
class Hello{
public:
Hello(){ cout << "Constructor called" << endl; }
~Hello(){ cout << "Destructor called" << endl; }
void greeting(){ cout << "Hello" << endl; }
};
2. 객체(Object)
: 객체를 설계할 때는 어떤 유형의 객체를 생성할 지 미리 정의하는 것이 중요
2.1. new keyword
객체를 생성하는 예약어로 Compile, Interpreter 과정에서 선언된 Class에 따른 객체(Instance)를 생성하고 이를 Memory에 할당

선언된 Class를 기반으로 객체를 생성하는 Instance화 작업을 수행하며 객체 간에 강력한 의존 관계를 갖는 구조적 문제 발생
-> 생성 패턴을 이용해 해당 문제를 해결할 수 있으며, 특히 Factory Pattern은 객체 생성을 별개의 Class로 구축해 위임 처리

[참고] Compile vs Interpreter
-. Compile: 고급 프로그래밍 언어(C, C++, JAVA, ...)로 작성된 Code를 기계어로 번역하는 과정으로, 이 과정은 한 번에 이루어져 실행 가능한 독립적인 Binary File(Executable) 생성
-. 장점: Compile 과정이 미리 완료되어 있어 속도가 빠르며, 배포 시 Source Code가 필요하지 않음
-. 단점: Source Code가 수정되면 재 Compile이 필요하며, 개발 과정에서 Debugging이 어렵거나 느릴 수 있음
-. Interpreter: Source Code를 한 줄 씩 읽고 즉시 실행하는 방식으로, 실행 가능한 File을 생성하지 않으며 주로 Python, Javascript, Ruby 같은 언어에 사용
-. 장점: Debugging과 Source Code 수정이 용이하며, 실행 파일 없이 Source Code를 바로 실행할 수 있어 개발 속도가 빠름
-. 단점: Source Code를 실시간으로 해석해 실행 속도가 느릴 수 있으며, Source Code가 필요하기 때문에 배포 시 보안에 취약할 수 있음
2.2 객체 생성
1) Stack 기반 객체 생성: 객체가 Stack Memory에 생성되어 Scope를 벗어나면 객체가 자동으로 소멸되어 명시적으로 소멸자를 호출하거나 Memory를 해제할 필요 없음
#include <iostream>
using namespace std;
class Hello{
public:
Hello(){ cout << "Constructor called" << endl; }
~Hello(){ cout << "Destructor called" << endl; }
void greeting(){ cout << "Hello" << endl; }
};
int main(void){
Hello helloObj; // Stack 기반 객체 생성
helloObj.greeting(); // Member 함수 호출
return 0; // Program 종료 시 helloObj의 소멸자가 자동 호출
}
Output
Constructor called
Hello
Destructor called
2) Heap 기반 객체 생성: 객체가 Heap Memory에 생성되어 delete 연산자를 사용해 명시적으로 Memory를 해제하지 않으면 Memory 누수 발생 가능
#include <iostream>
using namespace std;
class Hello{
public:
Hello(){ cout << "Constructor called" << endl; }
~Hello(){ cout << "Destructor called" << endl; }
void greeting(){ cout << "Hello" << endl; }
};
int main(void){
Hello* helloObj = new Hello(); // Heap 기반 객체 생성
helloObj->greeting(); // Member 함수 호출
delete helloObj; // 객체 소멸(Memory 해제)
return 0;
}
Output
Constructor called
Hello
Destructor called
| 특징 | Stack 기반 객체 | Heap 기반 객체 |
| Memory 위치 | Stack | Heap |
| 생성 방식 | 일반 선언 ClassName Obj; |
new 연산자 사용 new ClassName; |
| 소멸 방식 | Scope를 벗어나면 자동 소멸 | delete로 명시적 해제 필요 |
| 사용 권장 | 간단하고 일반적인 객체 생성 | 복잡하거나 동적 생명주기 관리 시 |
| 속도 | 빠름 | 상대적으로 느림 |
| Memory 누수 위험 | 없음 | 있음(해제 누락 시) |
3. 의존성
3.1 객체 지향
: 부여된 책임 간의 관계를 설정하고 상호 동작을 수행하는 것
* 관계(Relationship): 객체 간 동작을 위해 접근하는 것으로 개별 객체는 요구되는 역할을 수행하기 위한 책임이 부여됨
1) 객체의 관계 성립 -> 객체 간 상호작용 발생
2) 문제 해결을 위해 책임감 있는 객체는 각각의 Sub 책임을 가진 다른 객체에 소속된 문제 해결 위임
-> 이 때 객체 간 대화(Message)를 주고 받으며 객체의 고유 기능 실행
3.2 의존성(Dependency)
: SW 개발에서 한 Component(또는 객체)가 다른 Component에 의존하는 관계로, 한 Class가 자신의 작업을 수행하기 위해 다른 Class나 외부 Resource에 접근하거나 사용하는 경우 두 Class 사이에 의존성이 있다고 함
-> 의존성이 많으면 System이 복잡해지고 유지보수가 어려워질 수 있으므로, 필연적일 수 있으나 관리 및 최적화 하는 것이 중요
3.2.1 직접 의존성: 한 Class가 다른 객체를 직접 생성하거나 사용하는 경우
#include <iostream>
using namespace std;
class Engine{
public:
void start(){ cout << "Engine started" << endl; }
};
class Car{
private:
Engine engine; // Car Class가 Engine에 의존
public:
void startCar(){
engine.start(); // Engine 객체 사용
cout << "Car is ready to drive" << endl;
}
};
int main(){
Car car;
car.startCar();
return 0;
}
Output
Engine started
Car is ready to drive
3.2.2 의존성이 많은 Code의 문제점
-. 높은 결합도(Coupling)
: Class 내에서 Class 이름을 직접 지정해 객체를 생성하는 경우로, Class 간 결합도가 많으면 하나의 변경이 다른 Class에도 영향을 줄 가능성 커짐
-> 강력한 객체의 결합 Code는 향후 유연한 Code 확장을 방해하고 변경과 수정을 어렵게 만드는 원인
-. 재사용성 저하
: 특정 Class가 다른 Class에 강하게 의존하면 독립적으로 재사용하기 어려워짐
-. Test 어려움
: 의존성이 강한 Class는 단위 Test(Unit Test)를 수행하기 어려워질 수 있음
3.2.3 의존성 관리 방법
1) 의존성 주입(Dependency Injection, DI)
: 객체가 필요한 의존성(다른 객체)을 직접 생성하지 않고 외부에서 주입 받는 설계 방식으로, 의존성 주입이 발생하면 객체는 일반이 아닌 복합 객체 형태의 모습을 갖게 됨
#include <iostream>
using namespace std;
class Engine{
public:
void start(){ cout << "Engine started" << endl; }
};
class Car{
private:
Engine* engine; // Pointer로 객체 참조
public:
// 생성자 초기화 리스트로 Car Class 생성자에서 Engine 객체의 Pointer e를 전달 받아 멤버 변수
// engine에 초기화(Car 객체 생성 시 Engine 객체 전달 필요)
Car(Engine* e): engine(e){} // 의존성 주입
void startCar(){
engine->start(); // Engine 객체 사용
cout << "Car is ready to drive" << endl;
}
};
int main(){
Engine engine; // Engine 객체 생성
Car car(&engine); // 의존성 주입
car.startCar();
return 0;
}
Output
Engine started
Car is ready to drive
[참고] 생성자 초기화 리스트(Syntax for Initializer List)
객체가 생성될 때 멤버 변수를 초기화하는 방법으로, 생성자 내부에서도 멤버 변수를 초기화할 수 있으나, 생성자 초기화 리스트가 더 효율적
Car(Engine* e){
engine = e; // 생성자 내부에서 객체 초기화
}
2) Interface 사용
: Class 간 결합도를 줄이기 위해 Interface를 사용해 의존성을 느슨하게 만듦
-> C++에서는 Interface를 직접적으로 지원하지 않지만 순수가상함수(Pure Virtual Function)를 가진 Class를 통해 Interface 구현
#include <iostream>
using namespace std;
// Interface 정의
class IEngine{
public:
virtual void start() = 0; // 순수가상함수(Interface)
virtual ~IEngine(){} // 가상 소멸자
{;
// Engine Class: IEngine Interface 구현
class Engine: public IEngine{
public:
void start() override{
cout << "Standard Engine started" << endl;
}
};
// Electric Engine Class: IEngine Interface 구현
class Electric Engine: public IEngine{
public:
void start() override{
cout << "Electric Engine started silently" << endl;
}
};
// Car Class
class Car{
private:
IEngine* engine; // IEngine Interface 참조
public:
Car(IEngine* e): engine(e){} // 의존성 주입
void startCar(){
engine->start(); // IEngine의 start() 호출
cout << "Car is ready to drive" << endl;
}
};
int main(){
Engine standardEngine; // Standard Engine 객체 생성
ElectricEngine electricEngine; // Electric Engine 객체 생성
Car car1(&standardEngine); // Standard Engine 주입
car1.startCar();
Car car2(&electricEngine); // Electric Engine 주입
car2.startCar();
return 0;
}
Output
Standard Engine started
Car is ready to drive
Electric Engine started
Car is ready to drive
3) 의존성 역전 원칙(DIP, Dependency Inversion Principle)
: 고수준 Module은 저수준 Module에 의존하지 않고 모두 추상화에 의존해야 함
4) DI Framework 사용
: Google Guide와 같은 DI Framework 사용
3.3 복합 객체
하나의 객체가 다른 객체를 포함하거나 참조하는 구조로, 종속적이고 연관 관계를 가짐
1) 포함관계 (Composition)
: 강한 관계로 객체가 다른 객체를 직접 포함하며, 포함된 객체는 전체 객체와 생명주기 공유
#include <iostram>
using namespace std;
// Korean Class
class Korean{
public:
string text() const { return "안녕하세요"; }
};
// Hello Class (포함관계)
class Hello{
private:
Korean korean; // Korean 객체 직접 포함 (포함관계)
public:
Hello(){}
// greeting Method
string greeting() const { return korean.text(); }
};
int main(){
Hello hello; // Hello 객체 생성 (Hello 객체 생성되면서 Korean 객체도 함께 생성됨)
cout << hello.greeting() << endl;
return 0;
}
Output
안녕하세요
2) 집합 관계 (Aggregation)
: 느슨한 관계로, 객체가 다른 객체를 참조하거나 포인터로 소유하며 포함된 객체는 독집적으로 생성 및 소멸되어 생명주기를 공유하지 않음
#include <iostream>
#include <memory>
using namespace std;
class Korean{
public:
string text() const { return "안녕하세요"; }
}
class Hello{
private:
shared_ptr<Korean> korean; // Korean 객체 참조 (집합 관계)
public:
Hello(shared_ptr<Korean> obj): korean(obj) {} // 외부에서 Korean 객체 전달 받음
string greeting() const { return korean -> text(); )
};
int main(){
shared_ptr<Korean> koreanObj = make_shared<Korean>(); // Korean 객체를 독립적으로 생성
Hello hello(koreanObj); // Korean 객체를 Hello 객체에 전달(생명주기를 공유하지 않음)
cout << hello.greeting() << endl;
return 0;
}Output
안녕하세요| 구분 | 포함 관계 | 집합 관계 |
| 객체 간 관계 | 한 객체가 다른 객체를 완전하게 소유 | 한 객체가 다른 객체를 참조만 함 |
| 생명주기 | 포함된 객체는 포함하는 객체가 소멸될 때 함께 소멸 | 포함된 객체는 독립적으로 존재 가능 |
| 설계 방법 | 포함된 객체를 Class의 멤버변수로 직접 선언 | 포함된 객체를 포인터 또는 스마트포인터로 참조 |
3.3.2 복합객체의 장단점
1) 장점
-. 모듈화: 전체와 부분으로 나누어 설계하면 Code의 재사용성과 유지보수성 증가
-. 확장성: 객체를 구성하는 부분 객체를 교체하거나 확장하기 용이
-. 캡슐화: 복합 객체 내부의 세부 사항을 숨기고 외부에는 필요한 동작만 제공
2) 단점
-. 의존성 증가: 복합객체와 구성요소 간의 강한 의존성으로 인해 변경이 전체에 영향을 줄 수 있음
-. 복잡성 증가: 객체 간의 관계를 설계하고 관리하는 데 추가적인 노력 필요
4 생성 패턴(Creational Pattern)
4.1 new keyword
: 선언된 Class를 기반으로 객체를 생성하는 Instance화를 수행하며 객체 간에 강력한 의존 관계를 갖는 구조적 문제 발생
4.2 생성 패턴(Creational Pattern)
: 객체 생성을 위임해 별개의 Class로 분리하고 Program 내에서 객체 생성이 필요한 경우 분리 설계된 Factory 객체에 생성을 위임함으로써 느슨한 결합 관계로 변경
* 공장(Factory): Design Pattern에서 객체를 생성하고 캡슐화해 위임하는 것
5 Factory Pattern
: 객체 생성 로직을 캡슐화해 Client Code가 직접 객체의 생성 방법을 알 필요 없도록 하는 Design Pattern
즉, 객체를 생성하는 공장을 만드는 Pattern으로 객체 생성을 위한 Interface를 제공하면서 실제 생성 작업은 Sub-Class나 Factory Class에서 수행해 느슨한 결합 관계로 변경
-. 장점: 개발 과정에서 Class의 이름이 변경되어도 Code를 일일히 수정하지 않고 Factory 객체를 통해 쉽게 변경 가능(유연성과 확장성 개선)
-. 단점: 객체 생성을 위임하는 데 별도의 Class가 필요
-> 단순 팩토리로 이 단점 보완 가능
5.1 느슨한 결합
: 객체 생성은 객체 간 결합 관계를 발생시키고, 객체 간에 의존성 부여
-> Factory Pattern에서는 Code에서 직접 Class의 이름을 지정해 객체를 생성하지 않으며, 별도의 객체에 필요한 객체를 생성하도록 책임을 위임하는 과정에서 중복 코드 정리
#include <iostream>
#include <memory>
using namespace std;
// 1 제품 Class 정의 (Korean & English)
class Language{
public:
// 객체의 불필요한 변경을 방지하고, Code의 안정성과 최적화를 향상시키기 위해 상수(const) 사용
virtual string text() const = 0; // 순수가상함수
virtual ~Language(){} // 가상소멸자
};
class Korean: public Language{
public:
string text() const override { return "안녕하세요"; }
};
class English: public Language{
public:
string text() const override { return "Hello"; }
};
// 2 Factory Class 정의
class Factory{
public:
static unique_ptr<Language> getInstance(const string& type){
cout << "Factory: 객체를 생성합니다" << endl;
if(type == "ko") return make_unique<Korean>(); // 스마트포인터를 사용해 객체 반환
else if(type == "en") return make_unique<English>();
return nullptr; // 잘못된 type이면 nullptr 반환
}
};
[참고] Static Method
Class의 Member 변수나 Method가 객체(Instance)에 종속되지 않고, Class 자체에 속하도록 만들 때 사용
즉, Class의 Instance를 생성하지 않고도 사용할 수 있는 변수나 Method를 정의할 때 유용
1) 객체를 생성하지 않고도 호출 가능
: Static Method는 Class의 Instance를 생성하지 않아도 바로 호출 가능
2) Memory 절약 (불필요한 객체 생성 방지)
: static keyword를 사용하면 객체 없이도 Class 자체에서 직접 함수 호출이 가능해 Memory 사용량을 줄일 수 있음
-> Factory Pattern에서는 단순히 객체를 생성해 반환하는 역할만 수행하므로 굳이 Factory 객체를 만들 필요 없음
3) 전역적인 기능 제공 (Utility Function)
: Static Method는 특정 객체의 상태와 무관하게 동작하는 함수를 만들 때 유용
즉, Class의 상태를 변경하지 않는 함수(Utility Function)일 경우, static을 붙이면 객체 없이도 호출할 수 있음
class Logger{
public: // 객체 없이 호출 가능
static void log(const string& message){
cout << "[LOG]: " << message << endl;
}
};
int main(){
Logger::log("Program이 시작되었습니다");
}4) Factory Pattern에서 객체 생성 통일
: Factory Pattern에서는 객체 생성을 Captulation 해 통일된 방식으로 관리
-> Factory Pattern에서 객체 생성을 담당할 때, 굳이 Factory 객체를 만들 필요가 없으므로 static method로 정의하는 게 좋음
5) Sigleton Pattern과 함께 사용 가능
* Singleton Pattern: Program에서 단 하나의 객체만 존재하도록 제한하는 Pattern
-> static method를 사용해 전역적으로 하나의 객체만 유지할 수 있도록 함
class Singleton{
private:
static unique_ptr<Singleton> instance; // 정적변수
Singleton(){} // 생성자 Private으로 숨김
public:
static Singleton& getInstance(){ // 정적 Method
if(!instance) instance = make_unique<Singleton>();
return *instance;
}
void showMessage(){ cout << "Singleton 객체입니다" << endl; }
};
// 정적변수 초기화
unique_ptr<Singleton> Singleton::instance = nullptr;
int main(){
Singleton& s1 = Singleton::getInstance();
Singleton& s2 = Singleton::getInstance();
s1.showMessage();
cout << (&s1 == &s2) << endl;
}Output
Singleton 객체입니다
1
[참고] 스마트 포인터(Smart Pointer)
C++ 표준 Library에서 제공하는 Pointer 객체로, 일반 포인터(*)와 비슷하게 동적 Memory를 관리하지만, Memory 해제를 자동으로 처리해 Memory 누수(Memory leak) 방지
1) 자동으로 Memory 관리
: 스마트포인터는 객체가 더 이상 필요하지 않을 때 소멸자에서 메모리를 자동으로 해제해 delete 호출을 직접 할 필요 없이 메모리 누수 방지
2) 예외 안정성
: 예외가 발생하거나 함수가 비정상으로 종료될 경우에도 자동으로 메모리 해제
* 스마트 포인터 종류
-. std::unique_ptr
: 객체의 유일한 소유권을 가지며 다른 unique_ptr에 복사할 수 없고 이동만 가능
#include <iostream>
#include <memory>
class Test{
public:
Test(){ std::cout << "Test created" << endl; }
~Test(){ std::cout << "Test destroyed" << endl; }
};
int main(){
std::unique_ptr<Test> ptr = std::make_unique<Test>();
return 0; // ptr이 범위를 벗어나면 Test 객체를 자동으로 파괴
}Output
Test created
Test destroyed
-. std::shared_ptr
: 객체의 공유된 소유권을 관리하며 참조 카운트를 사용해 객체에 대한 참조가 모두 소멸되었을 때 메모리 해제
#include <iostream>
#include <memory>
class Test{
public:
Test{ std::cout << "Test created" << endl; }
~Test{ std::cout << "Test destroyed" << endl; }
};
int main(){
std::shared_ptr<Test> ptr1 = std::make_shared<Test>();
std::shared_ptr<Test> ptr2 = std::make_shared<Test>();
// ptr1과 ptr2가 Test 객체 공유
std::cout << "Use count: " << ptr1.use_count() << endl; // 참조 카운트
return 0;
}Output
Test created
Use count: 2
Test destroyed
-. week_ptr
: shared_ptr의 순환 참조 문제를 해결하기 위해 사용되며 객체를 참조하되, 참조 카운트를 증가시키지 않으며 객체가 파괴
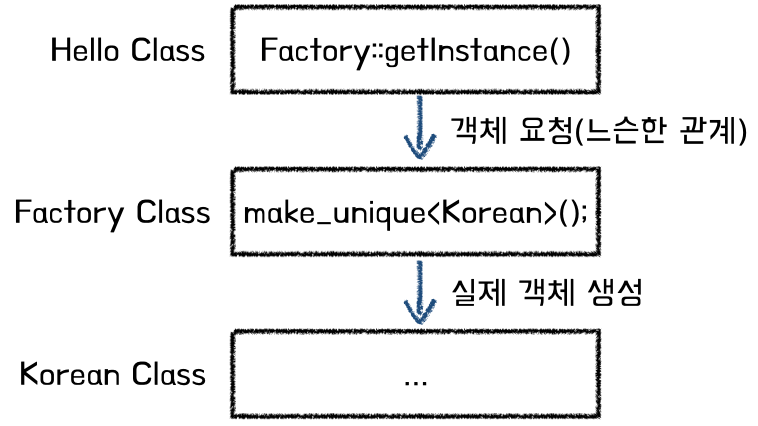
5.2 동적 팩토리(Dynamic Factory) Pattern
: 분리된 Factory Class의 객체를 통해 필요로 하는 모든 객체의 생성 위임
-> Code 자체에서 생성되는 강력한 의존 관계를 분리하고 느슨한 의존 관계로 변경
// 3 Hello Class 정의
class Hello{
public:
string greeting(const string& type){
unique_ptr<Language> lang = Factory::getInstance(type); // Factory를 호출해 객체 생성
if(lang){ return lang->text() }
return "유효하지 않은 타입입니다";
}
};
전체 Code
#include <iostream>
#include <memory>
using namespace std;
// 1 제품 Class 정의 (Korean & English)
class Language{
public:
// 객체의 불필요한 변경을 방지하고, Code의 안정성과 최적화를 향상시키기 위해 상수(const) 사용
virtual string text() const = 0; // 순수가상함수
virtual ~Language(){} // 가상소멸자
};
class Korean: public Language{
public:
string text() const override { return "안녕하세요"; }
};
class English: public Language{
public:
string text() const override { return "Hello"; }
};
// 2 Factory Class 정의
class Factory{
public:
static unique_ptr<Language> getInstance(const string& type){
cout << "Factory: 객체를 생성합니다" << endl;
if(type == "ko") return make_unique<Korean>(); // 스마트포인터를 사용해 객체 반환
else if(type == "en") return make_unique<English>();
return nullptr; // 잘못된 type이면 nullptr 반환
}
};
// 3 Hello Class 정의
class Hello{
public:
string greeting(const string& type){
unique_ptr<Language> lang = Factory::getInstance(type); // Factory를 호출해 객체 생성
if(lang){ return lang->text() }
return "유효하지 않은 타입입니다";
}
};
// 4 Main 함수(Client Code)
int main(){
Hello hello;
cout << hello.greeting("ko") << endl;
cout << hello.greeting("en") << endl;
cout << hello.greeting("fr") << endl;
return 0;
}Output
Factory: 객체를 생성해 반환합니다
안녕하세요
Factory: 객체를 생성해 반환합니다
Hello
Factory: 객체를 생성해 반환합니다
유효하지 않은 타입입니다
5.3 단순 팩토리(Simple Factory) Pattern = 정적 팩토리(Static Factory) Pattern
: Factory Pattern의 특징과 처리 로직을 간략하게 작성한 것으로 별개의 Factory Pattern 객체를 생성하는 것이 아닌 자신의 객체에 필요한 객체를 생성하는 전용 Method 추가
즉, 객체 생성 로직이 단일함수에 캡슐화
#include <iostream>
#include <memory>
using namespace std;
// Korean Class 정의
class Korean{
public:
string text() const{ return "안녕하세요"; }
};
// Hello Class 정의
class Hello{
public:
// greeting Method
string greeting() const{
// Factory Method 호출해 Korean 객체 생성
unique_ptr<Korean> ko = factory();
return ko->text();
}
// Factory Method (정적 Method)
static snique_ptr<Korean> factory(){
return make_unique<Korean>() // C++에서는 동적 객체를 반환할 때 스마트 포인터를 사용하는
// 것이 메모리 관리 측면에서 안전
}
};
// main 함수
int main(){
Hello hello;
cout << hello.greeting() << endl;
return 0;
}Output
안녕하세요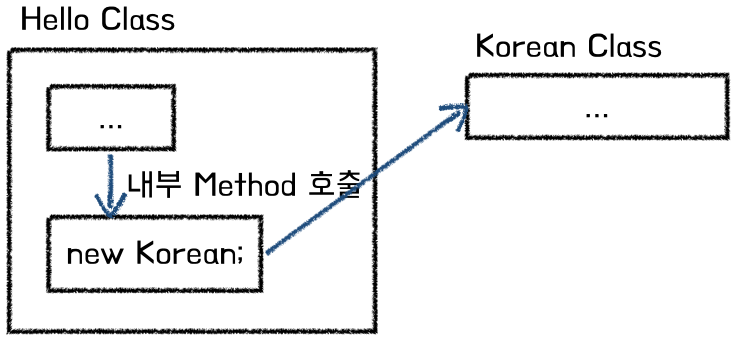
-. 장점: 객체 생성 과정이 복잡하지 않은 경우 추가 Class 파일을 생성하지 않고도 Factory Pattern 적용 가능
6 정리
Factory Pattern
: 객체 생성 시 확장과 수정을 쉽게 하기 위한 설계 방법으로 객체 생성 과정을 분리해 처리하기 때문에 객체 생성 과정에서 발생하는 new keyword의 문제점을 해결하고 느슨한 객체 생성 관리
다양한 Class의 객체 생성을 쉽게 처리하며 생성하는 객체를 정의할 수 없거나 변경이 있는 경우 객체 생성을 매우 유용하게 관리 가능
-> Factory Pattern이 Proxy Pattern과 결합하면 객체 생성을 위임받을 때 권한에 따라 접근하는 것을 제어할 수 있으며, 특정 객체 생성에서 보안 또는 권한 등의 처리가 필요할 때 응용 가능
[ Problem ] 객체지향개발에서 객체 간 의존성은 객체를 생성할 때마다 발생하며 Code에서 직접 생성한 객체는 의존성이 강력해 유지보수와 수정이 어려움
[ Solve ] 의존 관계가 강력한 결합 관계를 느슨한 결합 관계로 변경
[ 장점 ] 객체 생성을 다른 객체에 위임함으로써 내부적 결합을 제거하고 동적으로 객체 관리 가능
객체 생성 처리를 동적으로 위임하므로 향후 Class가 추가되거나 변경돼도 Code를 쉽게 수정 가능
[ 단점 ] Factory Pattern을 사용하면 객체를 직접 생성하는 것과 달리 Factory 객체를 통해 호출하는 처리 과정이 한 단계 더 필요하므로, 이는 불필요한 호출 증가로 Program 성능 저하를 초래할 수 있음
Simple Factory Pattern (단순 팩토리 패턴)
: Method를 통해 객체 생성을 관리해 가장 간단하고 깔끔하게 Class의 객체를 생성하는 의존적인 연관관계 해소 가능
- 저자
- 이호진
- 출판
- 한빛미디어
- 출판일
- 2020.10.05
'SW > Design Pattern' 카테고리의 다른 글
| 0. Design Pattern (1) | 2024.12.25 |
|---|